This is an application of searching songs with both audio and symbolic features extracted from song. Using manifold dimensionality reduction techniques, I designed interactive experience of exploring the space of multiple features.


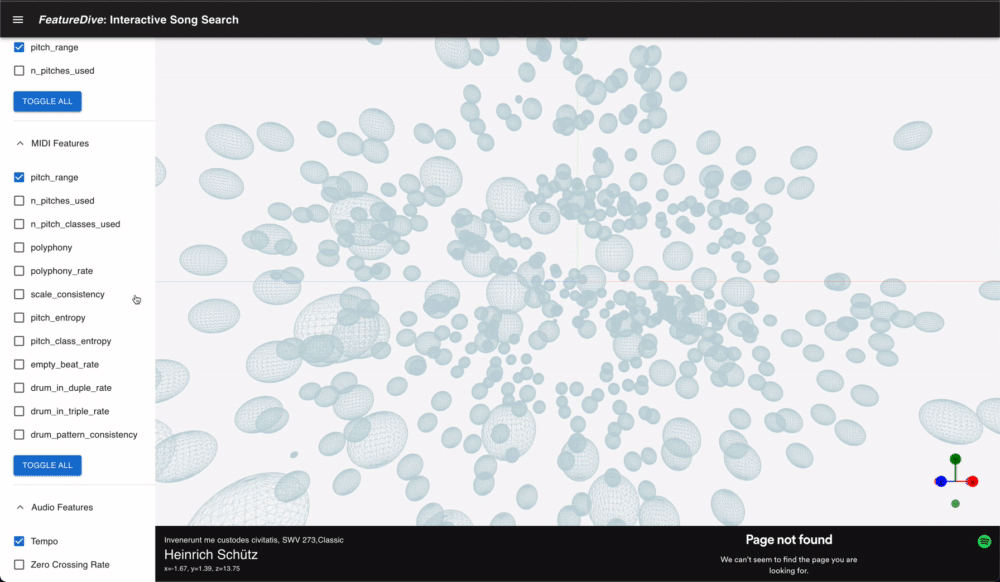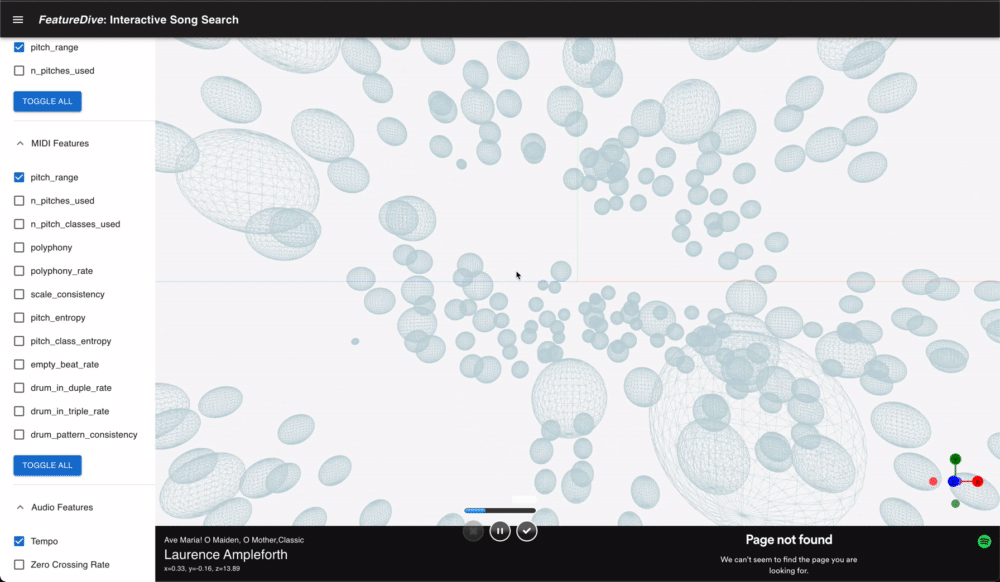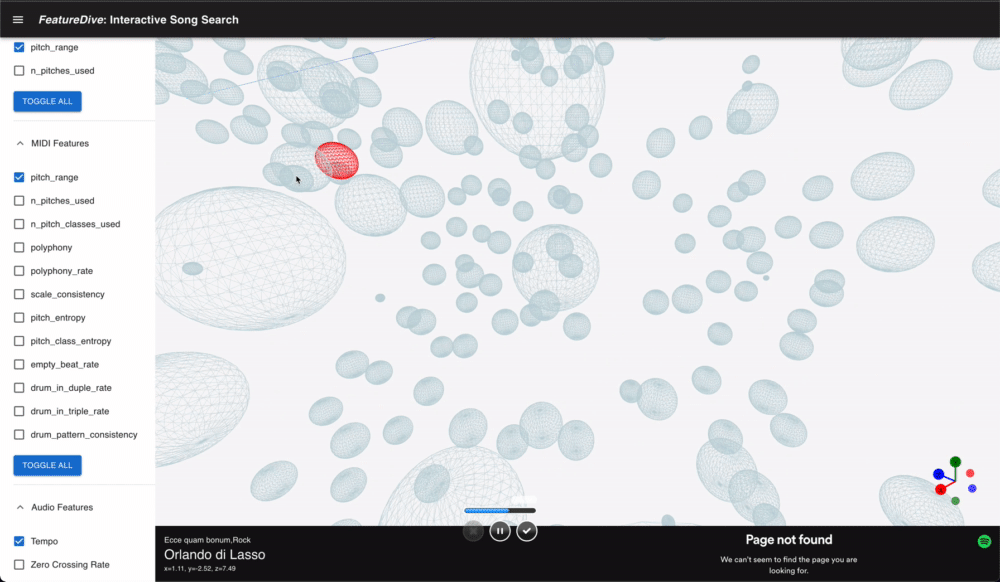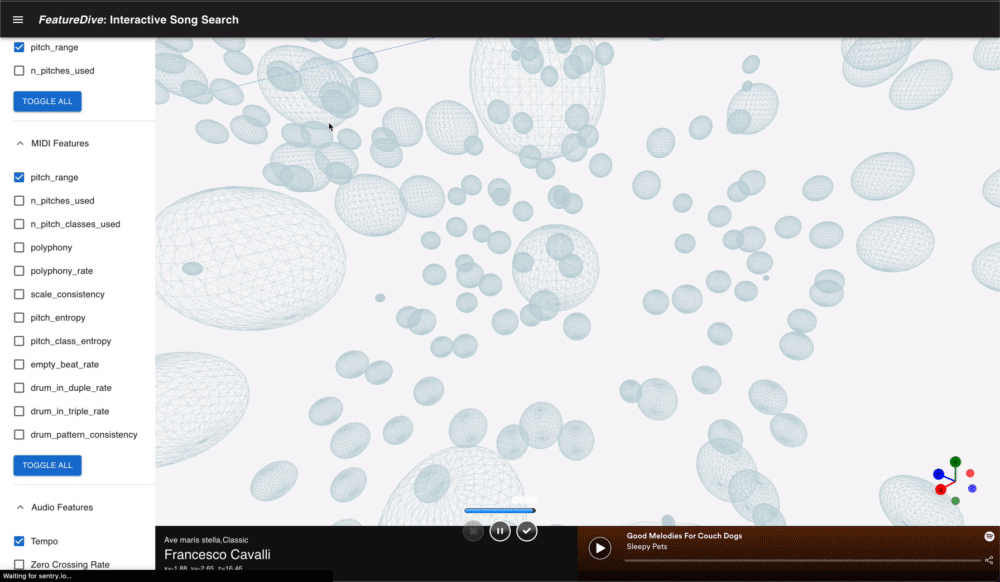
Implementation
https://github.com/atsukoba/interactive-music-searchThe backend is built with Python using Flask and PostgreSQL, processing music data with muspy and librosa.
The application frontend is React-based, utilizing Threejs (react-three-fiber).